

- 关于“预测”的一些见解
“预测”是依据历史数据对未来的某项任务进行“事先测算”。说到“测算”,在企业财务处理中有个年度财务计划的测算方式,术语叫做“预算”。 “预算”可以理解为“计划”,就是在企业尽力的前提下,测算未来年度收入、成本、费用、利润等指标能实现或控制到什么程度,并以此作为企业的经营计划、经营目标,并做出相关的制度、政策、措施的安排。
基于上述的认识,放到A股市场中,用个股价格作为例子的话,应用上述知识,我们首先能够知道的是,单只股票未来一段时间内,最好的情况以及最差的情况,股价的落点(涨跌停限制)。那么再结合其他的一些历史数据、信息(例如交易量、价格波动率、极值、平均收益率,价格均值等),来预测未来一段时间的价格可能落点的区间(忽略预测精度),或者给出一个较为合理的预期值,并针对这个预期值做出计划安排(小于、等于、大于的时候分别该怎么办)。这是在大部分时间里是能够做到的(黑天鹅不是每天都发生)。
- 为什么要使用DL技术
首先是数据的组织方式,我们传统的数据组织方式是一个二维化的矩阵,但是使用了DL技术,我们可以把数据组织方式变成三维化的矩阵,也就是张量(tensor)。很多人没有意识到这种数据组织方式所带来的好处,传统来说,我们只注意到单一特征与目标函数的关系,而忽略了特征与特征之间的关系。学过数据分析或者数据科学的人都会有一个感觉,在做特征工程时,经常会存在一种情况,就是看似没有什么关联的两个特征,其中一个却会强化或者放大另外一个特征与目标函数的关联性,这也就是说,数据中包含的信息,虽然无法被人所感知到,但在数学逻辑层面的确凸显了这种关联信息的价值。最终的目的就是提高了预测的精度。
- LSTM模型
LSTM模型是RNN的一种,其特点是在单一循环神经网络的基础上,构建出了长短记忆门,也就是着重于当前数据中存在的信息的同时,还可以发现和记忆存在于数据序列中的长依赖关系。这次比赛使用LSTM模型来预测,预测的标的是招商银行三天后的收盘价,也就是利用5月10日前的数据,来预测5月15日的收盘价。(中间有两天是周末)
- 使用DL技术做“预测”的缺点
股价价格的预测其实是一件极其不靠谱的事情。很多专业机构和量化交易的个人都是极力在规避价格预测这种做法的。原因有二,一是股市(无论哪个国家,哪种性质)随机突发事件太多,且突发事件对股市的影响力也是高度随机和不可预测的,也就是所谓的噪音多到让你怀疑人生。二是,连续变量作为预测目标是个糟糕的设计,因为这会使得预测空间太大,而导致模型需要搜索的空间无限大。这个见解来自于强化学习,强化学习的一个技术要点就是把需要预测的空间有限化,即便客观世界是连续而无限的,也需要采用类似于Tile coding的技术使其离散化,有限化。本着迎难而上,不成功也可以提高自己的初衷,尝试开始着手解决这一难题。
选择LSTM模型作为主算法来采用,是参考了kaggle上一个长期项目,预测美股收盘价的一个项目,其中第三名就是采用LSTM的。拿来测试之后,具有一定预测作用,但是预测精度不高,且性能不稳定。然后小组讨论后,是否就采用这个基本模型为核心,开展算法升级,得到一致同意后,于是确定了LSTM算法为核心算法,并做再次开发。
- 模型升级
LSTM模型之所有能够具有预测股价的能力,主要的还是模型本身捕捉了价格序列中的时序要素中所包含的信息。对于模型进行预测本身是完全没有问题的,而这次模型升级的根本目标是提升预测精度。
关于模型升级主要来自于两方面的,一是通过对模型的优化,二是数据优化。
(一)升级LSTM
LSTM模型大概有6种变形形式,主要的特点就是针对不同数据输入的类型。这里我选用了Multiple Input模型,也就是多序列输入,单序列输出。选择这个模型,对数据的构建也有非常好的促进作用,可以构建一个张量(多维数组),这个张量是一个5维张量,每个维度是一个特征数据,同时还可以按照N天的方式形成数据切片,这种设计基于两个原因:
一是数据中包含了大量信息,而越多的特征数据,提供的信息越多,多因子的雏形。
二是在保持多特征数据的基础上,保留时间序列数据的主要特点。也就是在不增加特征的情况,将特征信息成倍增加。
这种数据处理模式极大的优于诸多传统算法。诸多传统算法还是以单一样本为切片输入所有维度的数据,在捕捉时序中的信息方面是有所欠缺的。
(二)升级数据集
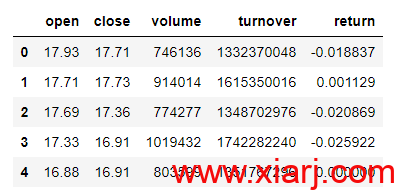
数据是从大智慧中取出的数据,数据时间段是2010年1月1日—2019年5月10日,数据包含open(开盘价)、close(收盘价)、volume(成交量)、turnover(成交额度)、return(日收益率)。特征选择了5个,原因是增加特征必然增加数据的获取难度,多因子模型的构建是基于丰富的数据供应基础上,在目前的这个比赛中,是不具备这个数据供应条件的,所以只用4个随处可得的基本特征数据加一个收益率的衍生变量。
按照N个交易日的模式,将数据变成一个shape为(M,N,5)的张量表。
- 代码解析
# 引入各种工具包
import pandas as pd
import numpy as np
np.set_printoptions(threshold=np.inf) #设置np数据在打印时能够完整输出,方便观察
from keras.models import Sequential
from keras.layers import LSTM,Dense
import keras
import matplotlib.pyplot as plt
# 全局参数,所有要调整的参数都在这里
dim=300 #输出维度数,也是LSTM的网络节点数
epochs=400 #训练代数(可以理解为训练次数)
days=20 #读取多少天的数据作为一次预测。例如读取20天的历史数据来预测未来1天的情况
batch_size = 535 #训练批次大小,就是一次性读取多少个样本进行一次运算,越大运算速度越快,但是占用内存和显存越大,根据自己的机器性能设置。同时该参数还决定梯度下降算法的下降步长数。
# 开始构建网络
n_steps = days #输入张量的维度数
n_features = 5 #输入张量的维度
model_2 = Sequential()
# 激活函数用relu
model_2.add(LSTM(dim, activation='relu',input_shape=(n_steps, n_features)))
# 输出层使用全连接层,只要一个输出节点
model_2.add(Dense(1))
#选择优化器和损失函数,优化器为线性规划算法,损失函数用的是高维空间测定距离的函数
model_2.compile(optimizer='rmsprop', loss='mse')
接下来开始构建数据,主要分为三个步骤完成
第一步导入数据
第二步生成数据切片,以及监督学习的标签,也就是三天后的收盘价。拆分训练序列训练集、测试集、标签
第三步载入模型进行训练
数据导入的基本操作,顺便观察下数据集的情况。
data = pd.read_csv('600036.csv')
data.head()
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2250 entries, 0 to 2249
Data columns (total 5 columns):
open 2250 non-null float64
close 2250 non-null float64
volume 2250 non-null int64
turnover 2250 non-null int64
return 2250 non-null float64
dtypes: float64(3), int64(2)
memory usage: 88.0 KB
构建两个处理数据生成张量表的函数,一个用带标签输出,另外一个只处理输入数据集,生成20×5的切片数据。
def processData(data,lb):
X,Y = [],[]
for i in range(len(data)-lb-1):
X.append(data[i:(i+lb),0])
try:
Y.append(data[(i+2+lb),0])
except:
Y.append(data[(i+lb),0])
return np.array(X),np.array(Y)
def pData(data,lb):
X,Y = [],[]
for i in range(len(data)-lb-1):
X.append(data[i:(i+lb)])
return np.array(X)
开始处理数据,同时对数据进行特征缩放处理,因为后面需要对特征缩放的数据进行逆运算,所以,要定义两个不同的特征缩放函数,否则后面针对输出标签逆运算会无法进行。
对数据进行特征缩放处理,将数据缩放到0-1区间内,这样可以加快训练结果的快速收敛。
from sklearn.preprocessing import MinMaxScaler
close = data['close']
cl = np.array(close)
cl = cl.reshape(cl.shape[0],1)
scl = MinMaxScaler()
sc2 = MinMaxScaler()
cl = scl.fit_transform(cl)
# 生成标签
_,y = processData(cl,days)
X = data.values
X = sc2.fit_transform(X)
X = pData(X,days)
对数据集进行训练集和测试集的拆分,我在这里偷了个懒,只生成了两组数据集。
y_train,y_test = y[:int(y.shape[0]*0.80)],y[int(y.shape[0]*0.80):]
X_train,X_test = X[:int(X.shape[0]*0.80)],X[int(X.shape[0]*0.80):]
拆分出来的数据是这个样子的
y_train的数据结构为: (1783,)
y_test的数据结构为: (446,)
X_train的数据结构为: (1783, 20, 5) # 1783个20×5的数据切片
X_test的数据结构为: (446, 20, 5) # 446个20×5的数据切片
张量表的结构为:(一个切片)
#执行模型训练
History = model_2.fit(X_train,y_train,batch_size=batch_size, epochs=epochs,
validation_data=(X_test,y_test),shuffle=False)
# 显示训练过程
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
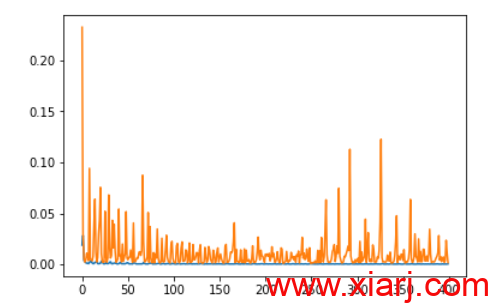
模型训练过程中的loss值,一个真实值的loss,一个是预测值的loss,可以明显的看到,两个loss已经快速收敛,但是预测值的loss并不稳定。在这种情况下,如果模型使用精确度来进行评估,明显已经不符合实际要求。故需要重新找到模型性能评估的方法。
模型训练完毕之后,需要对训练模型进行效果评估,大概的评估思路分为三步:
第一步单值预测检验
第二步序列预测检验
第三步用统计检验方法中的T检验对预测性能进行评估
(其实这里也可以使用均值方差误来进行评估)
#随机从测试集中抽取一个单一数据切片进行预测
act = []
pred = []
import random
i=random.randint(0,250)
Xt = model_2.predict(X_test[i].reshape(1,days,5))
print('预测值:{0}, 实际值:{1}'.format(Xt,y_test[i].reshape(-1,1)))
pred.append(Xt)
act.append(y_test[i])
预测值:[[0.7393236]], 实际值:[[0.74340618]]
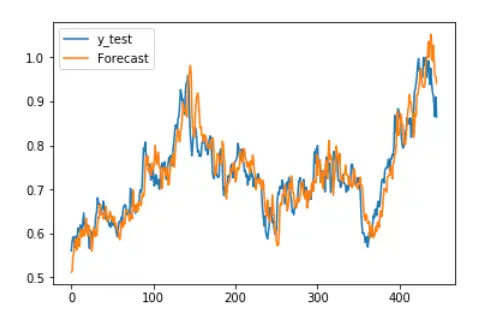
# 将测试集中的所有切片以序列的方式进行预测,查看预测结果与真实值的拟合情况。
Xt = model_2.predict(X_test)
fig = plt.gcf()
plt.plot(y_test.reshape(-1,1),label='y_test')
plt.plot(Xt,label='Forecast')
plt.legend()
# T检验中的差值统计,查看差值序列在统计挺行上的综合表现
a = y_test.reshape(-1,1)
b = Xt
c = a - b #实际值减去预测值
c = pd.DataFrame(c)
c.describe()
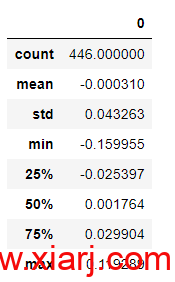
统计指标说明:
mean:代表测试集验证后的结果与真实情况的差值序列的平均值,也就是整体差异水平。正负无所谓,越趋近0越好。通过上述的结果来看,这次训练的模型预测结果于真实情况的整体误差已经小于1%,
std:标准差,代表均值在正负两个方向的分散程度,越小越好,说明结果比较集中,误差比较小,通过以上结果来看分散度仅有4.33%,在95%的置信度下。
- 模型保存
因为在训练模型时,确保能够产生最大的随机数,并未设置随机数种子。如果遇到性能较好的结果就运行下面的代码,以便将模型保存在本地。方便评估模型训练的最优参数。
path='my_model_2' # 请自行设置存储路径及文件名,例如:D:\\股票\\my_model
model_2.save(path+'.h5',include_optimizer=True) # 保存模型本体
model_2.save_weights(path + '_weights.h5') # 保存模型权重
- 模型载入执行预测
说明:由于神经网络依靠随机数,未设置随机数种子,所以每次训练结果均不相同。所以将性能较好的模型进行存储。
在实际使用时进行模型载入,分别查看预测结果。取最佳模型。
载入数据预测5月15日的close数值
filepath = 'my_model_1'
my_model = keras.models.load_model(filepath+'.h5')
p_1 = my_model.predict(X_test)
p_1 = scl.inverse_transform(p_1)
print('5月15日的close为:',p_1[-1])
5月15日的close为: [33.819942]
真实收盘价为33.63,预测值于真实值的误差为0.56%(预测值多于真实值,所以误差为正数)
- 总结
该模型最优参数组合,是通过几十次的反复训练所的得到的。在这个过程中还做了大量的调整和比对试验,就不做赘述,只将总结到的要点进行归纳阐述:
1. 因为构建的张量维度数并不是十分大,所以在网络的设计上,一个LSTM层加一个全连接层就已经足够了。如果我们的维度数可以增加到上百个,这个情况就可以继续增加隐藏层的数量,同时使用dropout层,丢弃部分冗余。
2. 对于LSTM模型,在做预测的时候,不能只给一个切片(单值)数据,这个预测的结果很大概率会产生偏差。正确的做法,应该是给一个切片序列,而你要预测的内容必须放置到最后一个。因为实验发现,LSTM模型的运行原理中,会根据上下连接的数据切片修正自己的长短记忆内容,也就是具备一定的推理能力,在使用这个模型时,需要给与足够的数据,让模型能够进行推理。
3. Y值(标签)的构建同样需要和X值(输入)的设计进行关联,因为这关系到你的训练数据是离散化,还是序列化,也关系到你的训练方式是可以离散化,还是序列化(时序化)。非常重要。这也是针对预测目标反推需要选择哪些数据组成数组的宗旨。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
